Data Mining ist eine interdisziplinäre Methodik, die sich u. a. statistische Methoden zu Nutze macht für die Auswertung von Zusammenhängen in großen, komplexen Datensätzen (Big Data). Ziel ist es, Muster, Verbindungen und Trends zu erkennen. Die Analyse großer Datenmengen verlangt nach entsprechend geeigneten Algorithmen und digitalen Tools. Data Mining umfasst eine nützliche Sammlung von Analysen, Methoden und Tools, welche in jedem datengetriebenen Unternehmen von Bedeutung sind. Dazu zählen z. B. Verfahren der Künstlichen Intelligenz wie maschinelles Lernen.
Data Mining ist eines der wichtigsten Verfahren zur Wissensgenerierung im digitalen Zeitalter. Vorhandene Datensätze werden mithilfe bestimmter Algorithmen untersucht, die Erkenntnisse aus der Mathematik, Informatik und Statistik kombinieren. Dabei erkennen entsprechende Programme, je nach Fragehorizont, Zusammenhänge und Muster, die sich in Analysen, Prognosen sowie Handlungsempfehlungen übersetzen lassen.
Der Begriff Data Mining – also wortwörtlich übersetzt Daten schürfen bzw. abbauen – ist deshalb nicht ganz korrekt. Daten werden nicht generiert, sondern analysiert. Richtiger wäre es demnach, von Knowledge Mining oder Intelligence Mining zu sprechen. Data Mining ist als Teilprozess des Knowledge Discovery in Databases (KDD)-Prozesses anzusehen, welcher sich mit der Wissensentdeckung in Datenbanken beschäftigt.
Im Vergleich zur klassischen Statistik geht es im Data Mining nicht um das Testen und Verifizieren von Hypothesen, sondern um das Aufstellen von Hypothesen. Diese bewegen sich aufgrund der analysierten Datenbestände nah an der Realität und ermöglichen damit wichtige unternehmerische Entscheidungen sowie das Lösen komplexer Probleme.
Als digitale Ausprägung klassischer Statistik werden im Data Mining vor allem fünf grundlegende statistische Methoden angewendet:
Diese Verfahren und Techniken werden im Data Mining ganzheitlich angewendet und zielbezogen genutzt. Dieses Ziel kann in zwei Hauptklassen unterteilt werden:
Data Mining unterstützt Unternehmen dabei, riesige Datenmengen zu analysieren. Aufgrund des missverständlichen Begriffs und des starken Zusammenhangs von Data Mining und Big Data wird oft nicht bemerkt, dass die Ansätze von vielen Unternehmen bereits seit Langem angewendet werden und unabhängig von der Branche oder der Unternehmensgröße funktionieren.
Sobald ein Unternehmen Datensätze generiert, die sich nicht mit Stift und Papier korrelieren lassen, gehören im Big Data-Umfeld angesiedelte Lösungen zur Standardkonfiguration des Datenmanagements. Grundsätzlich sind Big Data Tools und Data Mining-Methoden immer dann im Einsatz, wenn:
Das ist in der Praxis sowohl in den Bereichen Marketing und CRM entscheidend als auch bei der Entwicklung von neuen Medikamenten oder Versicherungsprodukten. Öffentliche Einrichtungen oder Regierungen können über Data Mining zum Beispiel Notfallplanung betreiben und Policy-Entscheidungen treffen.
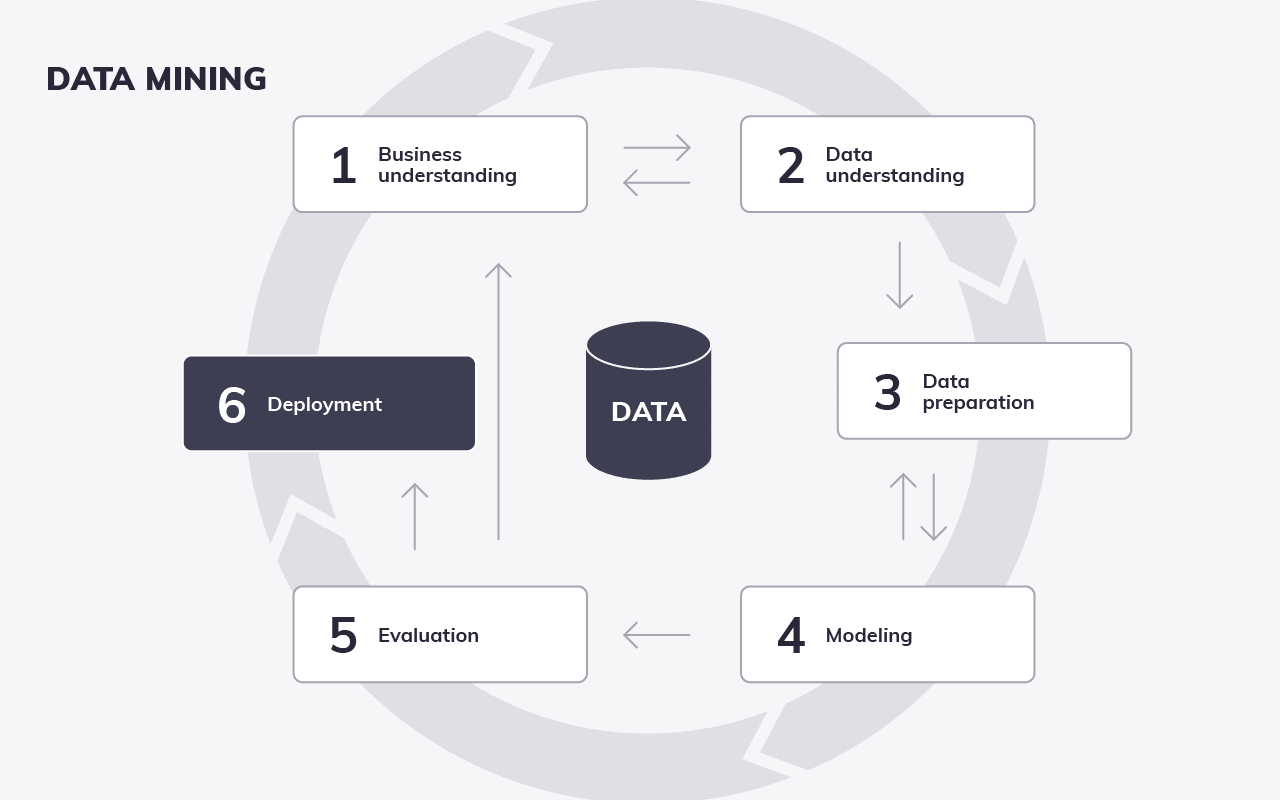
Als typisches Analyseverfahren folgt auch Data Mining den wichtigsten Phasen jeder Analysetätigkeit. Im Data Mining werden diese als CRISP-DM-Modell nach Shearer benannt:
Bis auf die Phasen 1 und 5 lassen sich alle Prozessschritte mit Tools und Software verkürzen, automatisieren sowie vereinfachen. Allerdings sind Phase 1 und 5 die wichtigsten Voraussetzungen bzw. Gründe für einen erfolgreichen Mining-Prozess mit Mehrwert.
Je nach Komplexität der Datenanalyse und der Spezialisierung der Anwender:innen bzw. Data Miners werden Algorithmen für die Analyse direkt in Programmiersprachen wie R oder Python geschrieben.
Die meisten Unternehmen verwenden GUI-basierte Lösungen mit entsprechenden Visualisierungstools. Softwarelösungen wie Microsoft Power BI sind zwar in ihren Analysehorizonten zwangsläufig begrenzter als selbst geschriebene Handlungsvorschriften. Sie benötigen jedoch weder Mining- noch Analysekenntnisse. Außerdem lassen sich die Ergebnisse über Dashboards und Visualisierungen sofort für jeden Anwender und jede Anwenderin aufbereiten.
Sprechen Sie jetzt mit unserem Cloud Analytics Experten und wir zeigen Ihnen, wie Sie Ihr Unternehmen auf die nächste Stufe bringen können.

Dürsin Kurt
CEO Cloud Analytics